Haskell #3: Function
Chương này sẽ đề cập đến một số cấu trúc cú pháp đẹp mắt của Haskell. Những cú pháp này sẽ giúp code của chúng ta trừu tượng và ngắn gọn hơn.
Pattern matching
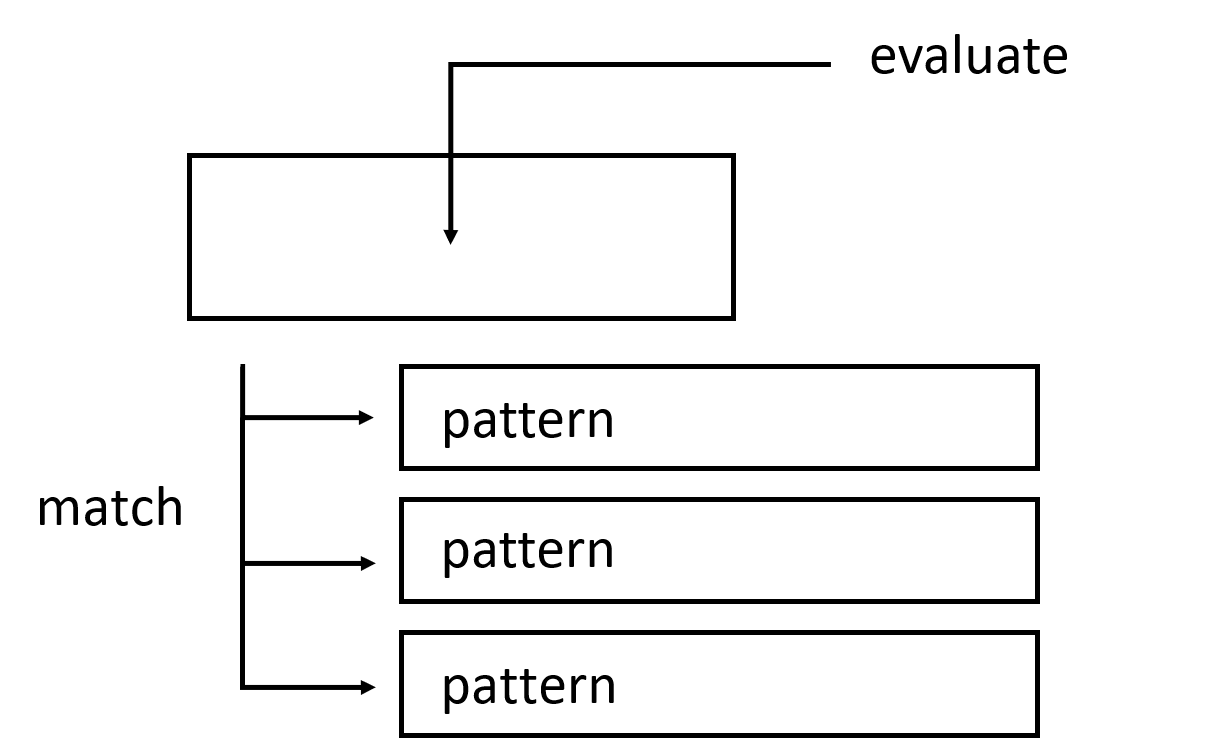
Và pattern matching sẽ là thứ đầu tiên. Pattern matching bao gồm việc chỉ định pattern cho từng case, tiếp đến là kiểm tra và deconstruct data dựa theo pattern đã cho.
Khi định nghĩa hàm, chúng ta có thể định nghĩa phần thân hàm riêng cho từng pattern. Điều này giúp code gọn gàng, đơn giản, và dễ đọc. Bạn có thể pattern matching với bất kỳ kiểu dữ liệu nào - number, character, List, tuple, v.v. Ví dụ về hàm kiểm tra xem số nhập vào có phải là 7 hay không.
lucky :: (Integral a) => a -> String
lucky 7 = "LUCKY NUMBER SEVEN!"
lucky x = "Sorry, you're out of luck, pal!"
Khi bạn gọi lucky, pattern sẽ được kiểm tra từ trên xuống dưới và khi nó khớp (match) với một pattern nào đó, phần thân hàm tương ứng sẽ được dùng, tương tự như câu lệnh switch - case trong ngôn ngữ khác. Cách duy nhất sử dụng được pattern thứ nhất là input phải bằng 7. Nếu không, pattern thứ hai sẽ được kích hoạt (vốn match với tát cả case còn lại). Tuy hàm này cũng có thể được thực hiện bằng một lệnh if nhưng nếu cấu trúc phức tạp hơn thì chuỗi lệnh if-then-else sẽ khá chằng chịt. Ví dụ, nếu có dùng thì:
sayMe :: (Integral a) => a -> String
sayMe 1 = "One!"
sayMe 2 = "Two!"
sayMe 3 = "Three!"
sayMe 4 = "Four!"
sayMe 5 = "Five!"
sayMe x = "Not between 1 and 5"
Lưu ý rằng nếu ta chuyển pattern cuối cùng lên đầu, nó sẽ catch tất cả các case và không kiểm tra các pattern còn lại nữa.
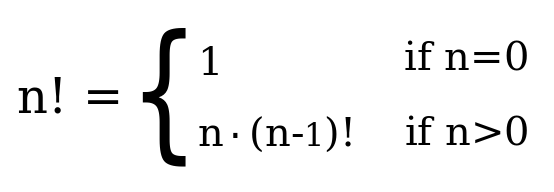
Còn nhớ hàm giai thừa mà ta đã viết trước đây chứ? Ta đã định nghĩa giai thừa của một số n là tích [1..n]. Ta cũng có thể tính giai thừa bằng đệ quy, đầu tiên phải định nghĩa giai thừa của 0 là 1, sau đó định nghĩa giai thừa của bất kì số nguyên nào thì bằng số nguyên đó nhân với giai thừa của số liền trước. Sau đây là cách viết trong Haskell:
factorial :: (Integral a) => a -> a
factorial 0 = 1
factorial n = n * factorial (n - 1)
Đây là lần đầu tiên ta sử dụng đệ quy. Đệ quy rất quan trọng trong Haskell và sau này ta sẽ xét nó kĩ hơn. Nhưng nói chung, đây là những điều sẽ xảy ra khi ta thử lấy giai thừa của 3 chẳng hạn. Nó sẽ đi tính 3 * factorial 2. Giai thừa của 2 là 2 * factorial 1, vì vậy bây giờ ta có 3 * (2 * factorial 1). factorial 1 là 1 * factorial 0, vì vậy ta có 3 * (2 * (1 * factorial 0)). Bây giờ định nghĩa giai thừa của 0 là 1 và vì nó catch pattern thứ nhất trước pattern thứ hai, nên nó trả về 1. Kết quả cuối cùng thì bằng 3 * (2 * (1 * 1)). Nếu ta mà viết pattern thứ hai lên trước pattern thứ nhất thì nó sẽ catch tất cả case, kể cả 0, và phép tính sẽ không bao giờ kết thúc. Đó là lý do thứ tự lại quan trọng trong việc chỉ định các pattern và tốt nhất là ta luôn chỉ định case cụ thể trước, sau đó mới đến các case chung chung.
Pattern matching cũng không phù hợp trong một số hoàn cảnh. Nếu ta định nghĩa một hàm như sau:
charName :: Char -> String
charName 'a' = "Albert"
charName 'b' = "Broseph"
charName 'c' = "Cecil"
Rồi thử gọi nó với input mà ta chưa định nghĩa, thì:
ghci> charName 'a'
"Albert"
ghci> charName 'b'
"Broseph"
ghci> charName 'h'
"*** Exception: Non-exhaustive patterns in function charName
Compiler phàn nàn rằng ta có tập pattern không chuẩn, và quả thực vậy. Khi compile pattern, ta luôn phải kẹp một pattern catch all để cho chương trình không bị crash nếu có ngoại lệ.
Pattern matching cũng có thể dùng cho tuple. Ví dụ như bài toán cộng hai vector, ta cộng từng thành phần. Đây là cách làm nếu ta xài pattern matching:
addVectors :: (Num a) => (a, a) -> (a, a) -> (a, a)
addVectors a b = (fst a + fst b, snd a + snd b)
Khá ngon, tuy nhiên còn một cách khác hay hơn. Ta hãy sửa lại hàm sao cho nó dùng đến pattern matching.
addVectors :: (Num a) => (a, a) -> (a, a) -> (a, a)
addVectors (x1, y1) (x2, y2) = (x1 + x2, y1 + y2)
Đó! Thế này hay hơn nhiều. Lưu ý rằng đây đã là một pattern catch-all. Kiểu của addVectors (trong cả hai case) là addVectors :: (Num a) => (a, a) -> (a, a) - > (a, a), vì vậy ta được đảm bảo hai pair sẽ là tham số.
fst và snd tách lấy các thành phần của một pair. Nhưng còn bộ ba thì sao? Không có hàm có sẵn nhưng ta có thể tự code một cách dễ dàng như sau.
first :: (a, b, c) -> a
first (x, _, _) = x
second :: (a, b, c) -> b
second (_, y, _) = y
third :: (a, b, c) -> c
third (_, _, z) = z
Dấu _ nghĩa là đếch quan tâm nó là gì. Điều này làm tôi nhớ ra là mình cũng có thể pattern matching trong dạng List comperhension. Hãy kiểm tra nhé:
ghci> let xs = [(1,3), (4,3), (2,4), (5,3), (5,6), (3,1)]
ghci> [a + b | (a, b) <- xs]
[4, 7, 6, 8, 11, 4]
Nếu một pattern match thất bại, nó sẽ tự nhảy sang phần tử kế tiếp.
Bản thân List cũng có thể dùng pattern matching. Bạn có thể match một List rỗng [] hay bất kì pattern nào có liên quan đến : và List rỗng. Vì [1,2,3] chỉ là viết tắt cho 1:2:3:[] nên một pattern kiểu như x:xs sẽ gán head của List cho x và phần còn lại cho xs, ngay cả khi chỉ có một phần tử (lần duyệt cuối xs sẽ là List rỗng []).
Lưu ý: Pattern x:xs được dùng đến rất nhiều, đặc biệt với đệ quy. Nhưng các pattern có chứa : chỉ match với các List có độ dài 1 hoặc hơn. Nếu bạn muốn gán, chẳng hạn, 3 phần tử đầu vào một số biến và phần còn lại vào một biến khác, bạn có thể dùng cách viết kiểu như x:y:z:zs. Nó sẽ chỉ match với List nào có 3 phần tử hoặc hơn.
Bây giờ khi đã biết cách dùng pattern matching với List, hàm head được định ngĩa như sau.
head' :: [a] -> a
head' [] = error "Can't call head on an empty List, dummy!"
head' (x:_) = x
KIểm tra xem nó có hoạt động không:
ghci> head' [4,5,6]
4
ghci> head' "Hello"
'H'
Tốt rồi! Lưu ý rằng nếu bạn muốn gán vài biến khác nhau (ngay cả khi một trong số chúng chỉ là _ và thực ra không gán gì), ta phải kẹp chúng vào giữa cặp ngoặc tròn. Cũng lưu ý hàm error mà ta đã dùng. Nó nhận vào string và phát sinh ra lỗi thực thi, dùng chuỗi đó như là lời thông báo cho biết lỗi xảy ra thuộc loại gì. Nó khiến cho chương trình crash, vì vậy dùng nhiều quá sẽ không tốt.
Một ví dụ khác với List.
tell :: (Show a) => [a] -> String
tell [] = "The List is empty"
tell (x:[]) = "The List has one element: " ++ show x
tell (x:y:[]) = "The List has two elements: " ++ show x ++ " and " ++ show y
tell (x:y:_) = "This List is long. The first two elements are: " ++ show x ++ " and " ++ show y
Hàm này an toàn vì nó xử lý cả List rỗng, List một phần tử, List với hai phần tử, và nhiều hơn hai phần tử. Lưu ý rằng (x:[]) và (x:y:[]) có thể được viết lại thành [x] và [x,y] (nếu viết tắt, ta không cần đến cặp ngoặc tròn). Ta không thể viết lại (x:y:_) với cặp ngoặc vuông vì nó cần phải match với một List có độ dài hai phần tử hoặc hơn.
Ví dụ về pattern matching để tính length List bằng đệ quy:
length' :: (Num b) => [a] -> b
length' [] = 0
length' (_:xs) = 1 + length' xs
Cách này cũng tương tự như hàm giai thừa mà ta viết trước đây. Đầu tiên ta định nghĩa kết quả cho List rỗng. Đây cũng được gọi là điều kiện biên (edge condition). Sau đó trong pattern thứ hai ta tách rời List thành head và tail. Ta nói rằng chiều dài thì bằng 1 cộng với length’ tail. Ta dùng _ để match với head vì thực ra không cần biết head là gì. Cũng lưu ý rằng ta đã xử lý tất cả các pattern có thể đối với List. Pattern thứ nhất match với một List rỗng và pattern thứ hai match với trường hợp còn lại.
Hãy xem điều gì xảy ra khi ta gọi length’ đối với “ham”. Trước hết, nó sẽ kiểm tra xem đây có phải là List rỗng không. Vì không phải, nên nó vào pattern thứ hai, và match với pattern này, chiều dài sẽ bằng 1 + length' "am" (vì ta chia nó thành head và tail sau đó bỏ head đi). Được rồi. length’ của “am” cũng tương tự, và bằng 1 + length' "m". Như hiện giờ ta có 1 + (1 + length' "m"). length' "m" bằng 1 + length' "" (cũng có thể được viết là 1 + length' []). Và ta đã định nghĩa length' [] bằng với 0. Vì vậy cuối cùng ta có 1 + (1 + (1 + 0)).
Ví dụ khác về hàm sum. Biết rằng tổng của List rỗng bằng 0 và tổng của List thì bằng head cộng với tổng của tail. Nếu viết hẳn ra, ta có:
sum' :: (Num a) => [a] -> a
sum' [] = 0
sum' (x:xs) = x + sum' xs
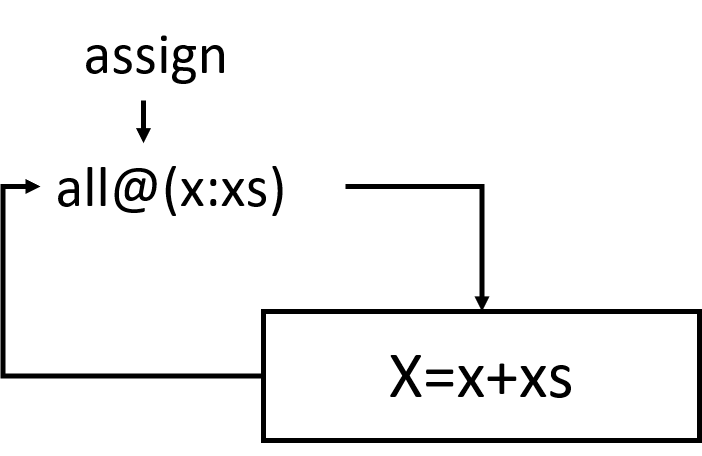
Ngoài ra cũng có một cú pháp được gọi là as pattern. Thủ tục là đặt tên biến và dấu @ phía trước một pattern. Chẳng hạn, pattern xs@(x:y:ys). Pattern này sẽ match đúng như x:y:ys và chúng ta lấy lại được List ban đầu bằng xs thay vì tự gõ lại cả biểu thức x:y:ys trong phần thân hàm. Sau đây là một ví dụ “mì ăn liền”:
capital :: String -> String
capital "" = "Empty string, whoops!"
capital all@(x:xs) = "The first letter of " ++ all ++ " is " ++ [x]
ghci> capital "Dracula"
"The first letter of Dracula is D"
Thông thường ta dùng pattern as để dùng lại đối tượng đầu vào trong phần thân hàm dễ hơn.
Một điều nữa - bạn không thể dùng ++ trong pattern matching. Nếu thử pattern matching với (xs ++ ys) thì chẳng có ý nghĩa vì compiler sẽ không biết ranh giới giữa 2 List (giả sử List ban đầu có 10 phần tử, vậy xs sẽ có 3, 4 hay 7 phần tử?). Sẽ có nghĩa hơn nếu chúng ta ghi rõ ràng là (xs ++ [x,y,z]) hoặc đơn thuần là (xs ++ [x]), nhưng vì bản chất của List, bạn không thể làm việc đó.
Guard

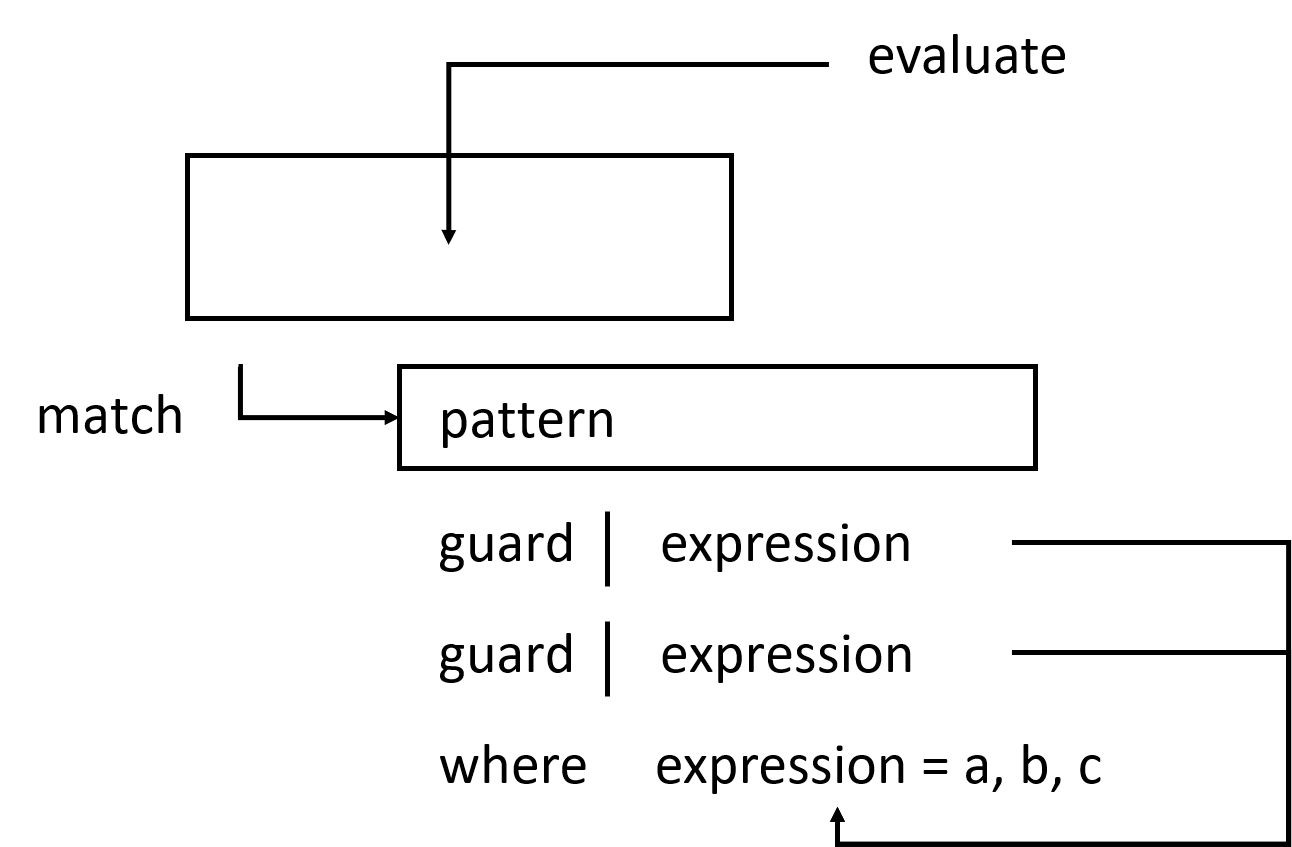
Trong khi pattern là một cách để đảm bảo rằng một giá trị phù hợp với một dạng nào đó rồi deconstruct nó, guard lại là cách kiểm tra thuộc tính nào đó của một giá trị (hoặc vài giá trị) là đúng hay sai. Nghe có vẻ rất giống lệnh if và có nhiều điểm tương đồng với if. Nhưng guard dễ đọc hơn khi chương trình có nhiều điều kiện khác nhau, đồng thời nó cũng kết hợp rất tốt với pattern matching.
Thay vì giải thích cú pháp của guard, ta sẽ tạo một hàm đơn giản để chửi tùy theo BMI (body mass index, chỉ số khối lượng cơ thể) của bạn. BMI bằng với cân nặng chia cho chiều cao bình phương. Nếu có BMI thấp hơn 18.5 thì được coi là nhẹ cân. Nếu từ 18.5 đến 25 là bình thường. 25 đến 30 đồng nghĩa với béo còn hơn 30 là béo phì.
bmiTell :: (RealFloat a) => a -> String
bmiTell bmi
| bmi <= 18.5 = "You're underweight, you emo, you!"
| bmi <= 25.0 = "You're supposedly normal. Pffft, I bet you're ugly!"
| bmi <= 30.0 = "You're fat! Lose some weight, fatty!"
| otherwise = "You're a whale, congratulations!"
Guard được kí hiệu bởi dấu | theo sau biến hàm cùng các tham số. Thường thì chúng được viết thụt đầu dòng và xếp thẳng hàng. Guard về cơ bản là một biểu thức boolean. Nếu nó trả về True, phần thân hàm tương ứng sẽ được dùng đến. Nếu nó False, thì chuyển đến guard tiếp theo và cứ như vậy. Nếu ta gọi hàm này với 24.3, thì đầu tiên nó sẽ kiểm tra xem liệu số này có nhỏ hơn hoặc bằng 18.5 không. Vì không phải, nên nó lọt sang guard sau. Việc kiểm tra được thực hiện với chốt thứ hai và vì 24.3 nhỏ hơn 25.0 nên chuỗi thứ hai được trả lại.
Giống một cây if else lớn trong ngôn ngữ lập trình khác, chỉ khác ở chỗ cách này hay hơn và dễ đọc hơn nhiều. Dù cây if else thường dễ bị “ghét” nhưng đôi khi bài toán không thể tránh khỏi việc dùng cấu trúc này. Dùng guard là cách làm thay thế rất tiện lợi.
Nhiều trường hợp guard cuối cùng là otherwise vì otherwise được định nghĩa đơn giản là catch - all. Rất giống với pattern, tức là nếu tất cả guard của hàm đều False (mà ta chưa đặt guard otherwise để catch - all) thì việc đánh giá sẽ chuyển sang pattern tiếp theo. Đó là cách kết hợp nhịp nhàng giữa pattern và guard. Nếu không có guard hay pattern nào khớp thì lỗi sẽ được bung.
Dĩ nhiên ta có thể dùng guard với các hàm nhận vào bao nhiêu tham số tùy ý. Thay vì để cho người dùng tự tính BMI của mình trước khi gọi hàm, ta hãy sửa lại hàm này sao cho nó nhận vào chiều cao và cân nặng rồi tính BMI.
bmiTell :: (RealFloat a) => a -> a -> String
bmiTell weight height
| weight / height ^ 2 <= 18.5 = "You're underweight, you emo, you!"
| weight / height ^ 2 <= 25.0 = "You're supposedly normal. Pffft, I bet you're ugly!"
| weight / height ^ 2 <= 30.0 = "You're fat! Lose some weight, fatty!"
| otherwise = "You're a whale, congratulations!"
Để xem tôi có béo hay không …
ghci> bmiTell 85 1.90
"You're supposedly normal. Pffft, I bet you're ugly!"
A, tôi không béo. Nhưng Haskell chửi tôi xấu. Chả sao!
Lưu ý rằng không có dấu = nào ngay trước guard đầu tiên.
Một ví dụ rất đơn giản khác: hàm max, nó nhận hai đối tượng có thể so sánh được rồi trả lại đối tượng lớn hơn trong số chúng.
max' :: (Ord a) => a -> a -> a
max' a b
| a > b = a
| otherwise = b
Guard cũng có thể viết trên cùng một dòng, mặc dù tôi không khuyến khích bạn làm vậy vì nó khó đọc hơn. Ví dụ thế này:
max' :: (Ord a) => a -> a -> a
max' a b | a > b = a | otherwise = b
Ối! Chẳng hề dễ đọc chút nào! Tiếp tục này: ta hãy lập lấy hàm compare bằng cách dùng guard.
myCompare :: (Ord a) => a -> a -> Ordering
a `myCompare` b
| a > b = GT
| a == b = EQ
| otherwise = LT
ghci> 3 `myCompare` 2
GT
Lưu ý: Chẳng những gọi được hàm theo dạng trung tố với các dấu nháy ngược, ta còn có thể định nghĩa chúng dùng dấu nháy ngược. Đôi khi cách này dễ đọc hơn.
Biểu thức where
Ở mục trước, ta đã định nghĩa hàm tính BMI:
bmiTell :: (RealFloat a) => a -> a -> String
bmiTell weight height
| weight / height ^ 2 <= 18.5 = "You're underweight, you emo, you!"
| weight / height ^ 2 <= 25.0 = "You're supposedly normal. Pffft, I bet you're ugly!"
| weight / height ^ 2 <= 30.0 = "You're fat! Lose some weight, fatty!"
| otherwise = "You're a whale, congratulations!"
Có một thứ hơi lấn cấn là ta đã lặp cú pháp lại 3 lần. Vì vậy, ta có thể sửa lại như sau:
bmiTell :: (RealFloat a) => a -> a -> String
bmiTell weight height
| bmi <= 18.5 = "You're underweight, you emo, you!"
| bmi <= 25.0 = "You're supposedly normal. Pffft, I bet you're ugly!"
| bmi <= 30.0 = "You're fat! Lose some weight, fatty!"
| otherwise = "You're a whale, congratulations!"
where bmi = weight / height ^ 2
Tôi đã đặt từ khóa where sau các guard (thường thì where ngang với các dấu |) và sau đó ta định nghĩa biến hoặc hàm. Những biến này có hiệu lực cho tất cả guard. Nếu có ý định tính BMI khác đi một chút, ta chỉ phải sửa lại một lần. Nó cũng giúp code dễ đọc hơn bằng cách gọi tắt biểu thức và chương trình chạy nhanh hơn vì bmi ở đây chỉ được tính một lần.
bmiTell :: (RealFloat a) => a -> a -> String
bmiTell weight height
| bmi <= skinny = "You're underweight, you emo, you!"
| bmi <= normal = "You're supposedly normal. Pffft, I bet you're ugly!"
| bmi <= fat = "You're fat! Lose some weight, fatty!"
| otherwise = "You're a whale, congratulations!"
where
bmi = weight / height ^ 2
skinny = 18.5
normal = 25.0
fat = 30.0
Biểu thức được định nghĩa ở phần where của hàm chỉ có tác dụng trong hàm đó, nên ta không phải lo lắng rằng nó ảnh hướng tới các hàm khác hay không. Lưu ý rằng tất cả đều được xếp thẳng hàng. Nếu không xếp như vậy thì Haskell sẽ bị lẫn vì khi đó nó không biết rằng các biến này cùng khối lệnh.
Giá trị được gán vào biến trong where không được chia sẻ giữa các pattern khác nhau trong cùng một hàm. Nếu bạn muốn nhiều pattern của cùng một hàm chia sẻ một biến nào đó, bạn phải khai báo global.
Bạn cũng có thể gán các giá trị trong where theo kiểu pattern matching! Ta có thể viết lại đoạn có where trong hàm trên như sau:
...
where
bmi = weight / height ^ 2
(skinny, normal, fat) = (18.5, 25.0, 30.0)
Hãy tạo một hàm trong đó nhận vào họ và tên rồi trả lại chữ viết tắt.
initials :: String -> String -> String
initials firstname lastname = [f] ++ ". " ++ [l] ++ "."
where
(f:_) = firstname
(l:_) = lastname
Ta có thể thực hiện pattern matching trực tiếp ở tham số hàm (như vậy sẽ ngắn hơn và rõ hơn) nhưng ở đây ta chỉ thấy rằng có thể thực hiện thao tác này trong khi gán giá trị ở khối ‘where’. Cũng giống như việc ta vừa định nghĩa các hằng số trong khối “where”, bạn cũng có thể định nghĩa các hàm. Để nhất quán, tạo một hàm nhận vào một List pair weight - height rồi trả lại một List chỉ số BMI.
calcBmis :: (RealFloat a) => [(a, a)] -> [a]
calcBmis xs = [bmi w h | (w, h) <- xs]
where bmi weight height = weight / height ^ 2
Và đó là tất cả những gì cần làm! Lý do ta phải giới thiệu bmi như một hàm trong ví dụ này là vì ta không thể chỉ tính một BMI từ tham số của hàm. Ta phải kiểm tra List được truyền vào hàm và mỗi pair trong List thì có một BMI riêng.
Việc gán trong where cũng có thể được lồng. Có một cách viết thông dụng để tạo một hàm rồi định nghĩa hàm trợ giúp nào đó trong vế where, rồi chuyển vào hàm này hàm trợ giúp.
Câu lệnh let - in
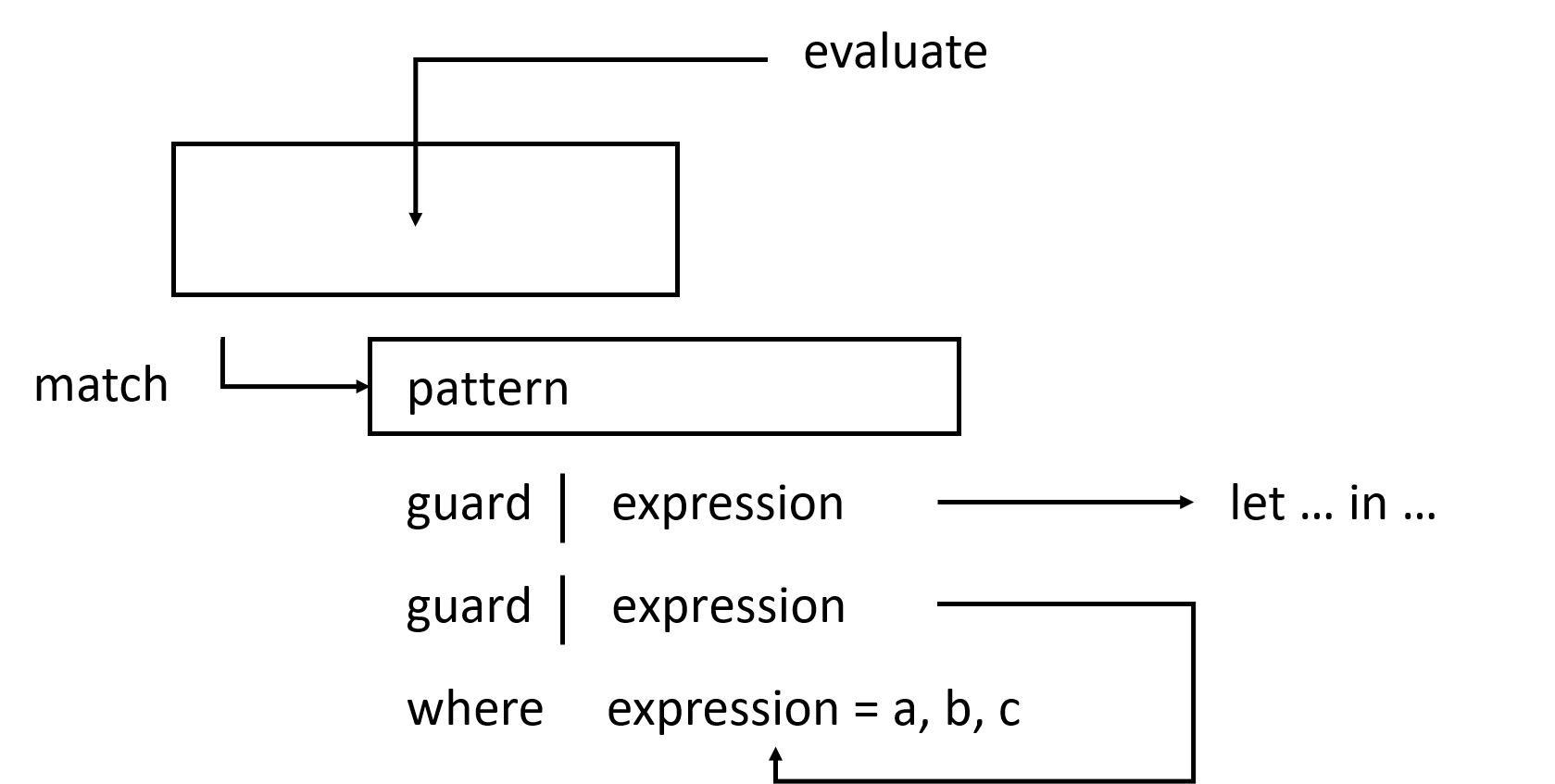
Rất giống với gán biến where là let. Gán biến dùng where là cú pháp cho phép bạn gán giá trị vào biến ở cuối hàm và toàn bộ hàm có thể thấy được biến đó, kể cả mọi guard. Còn let là một biểu thức, nhưng có tính local, và không truy cập được từ guard khác. Như bất kì cấu trúc nào khác trong Haskell được dùng để gán, let cũng có thể kết hợp với pattern matching. Hãy xem nó hoạt động ra sao. Đây là cách mà ta định nghĩa hàm tính diện tích bề mặt khối trụ tròn cho trước chiều cao và bán kính mặt đáy:
cylinder :: (RealFloat a) => a -> a -> a
cylinder r h =
let sideArea = 2 * pi * r * h
topArea = pi * r ^2
in sideArea + 2 * topArea
Dạng cú pháp là let <bindings> in <expression>. Biến được định nghĩa trong phần let thì biểu thức ở phần in đều truy cập tới được. Bạn thấy đấy, ta cũng có thể định nghĩa được bằng where. Vậy có gì khác biệt? Có thể thấy let đặt biến được gán lên trước, rồi mới đến biểu thức sử dụng chúng, trong khi where có thứ tự ngược lại.
Khác biệt nữa là bản thân let là biểu thức, còn where chỉ là cấu trúc cú pháp.
ghci> [if 5 > 3 then "Woo" else "Boo", if 'a' > 'b' then "Foo" else "Bar"]
["Woo", "Bar"]
ghci> 4 * (if 10 > 5 then 10 else 0) + 2
42
Bạn cũng có thể làm như vậy với let.
ghci> 4 * (let a = 9 in a + 1) + 2
42
Chúng còn có thể được dùng để giới thiệu hàm trong phạm vi local:
ghci> [let square x = x * x in (square 5, square 3, square 2)]
[(25,9,4)]
Nếu ta muốn gán nhiều biến trên cùng dòng lệnh, rõ ràng ta không thể xếp chúng theo dạng cột. Đó là vì sao ta có thể ngăn cách chúng bằng dấu ;.
ghci> (let a = 100; b = 200; c = 300 in a*b*c, let foo = "Hey "; bar = "there!" in foo ++ bar)
(6000000,"Hey there!")
Bạn không cần phải đặt ; sau lần gán cuối cùng nhưng nếu muốn thì cũng không sao. Như chúng tôi đã nói từ trước, bạn có thể xài pattern matching với let. Chúng rất có ích khi cần chia một tuple ra từng thành phần rồi gán mỗi thành phần với biến.
ghci> (let (a,b,c) = (1,2,3) in a+b+c) * 100
600
Bạn cũng có thể đặt let bên trong List comperhension. Hãy viết lại ví dụ trước đây để tính List các cặp cân nặng - chiều cao nhưng dùng let bên trong List comperhension thay vì định nghĩa hàm phụ bằng where.
calcBmis :: (RealFloat a) => [(a, a)] -> [a]
calcBmis xs = [bmi | (w, h) <- xs, let bmi = w / h ^ 2]
Ta có thể kèm let bên trong List comprehension, như vai trò vị ngữ, chỉ khác là nó không thực hiện thao tác filter List, mà chỉ gán. Các biến được định nghĩa let bên trong List comprehension đều có thể sử dụng bởi hàm output (phần phía trước dấu |) và tất cả vị ngữ theo sau phép gán. Vì vậy ta có thể làm cho hàm vừa viết chỉ trả lại BMI cho người béo:
calcBmis :: (RealFloat a) => [(a, a)] -> [a]
calcBmis xs = [bmi | (w, h) <- xs, let bmi = w / h ^ 2, bmi >= 25.0]
Ta không thể dùng bmi trong (w, h) <- xs vì nó được định nghĩa trước let.
Ta bỏ qua phần in của let khi dùng chúng trong List comprehension. Tuy vậy, ta có thể dùng let in trong vị ngữ và các biến sẽ chỉ được dùng trong vị ngữ đó. Phần in cũng có thể bỏ qua được khi định nghĩa hàm và hằng số trực tiếp trong GHCI. Nếu ta làm như vậy, thì các biến có phạm vi trong suốt một câu lệnh thực thi trên GHCI.
ghci> let zoot x y z = x * y + z
ghci> zoot 3 9 2
29
ghci> let boot x y z = x * y + z in boot 3 4 2
14
ghci> boot
<interactive>:1:0: Not in scope: `boot'
Nếu gán giá trị bằng let hay như vậy thì sao ta không dùng nó để thay hẳn cho where? Vì let là biểu thức và phạm vi local nên chúng không thể dùng chung giữa các guard. Có người thích where hơn vì các biến theo sau hàm, phần thân hàm gần với biến hơn và tùy theo từng người, cách này có thể dễ đọc hơn.
Case expression
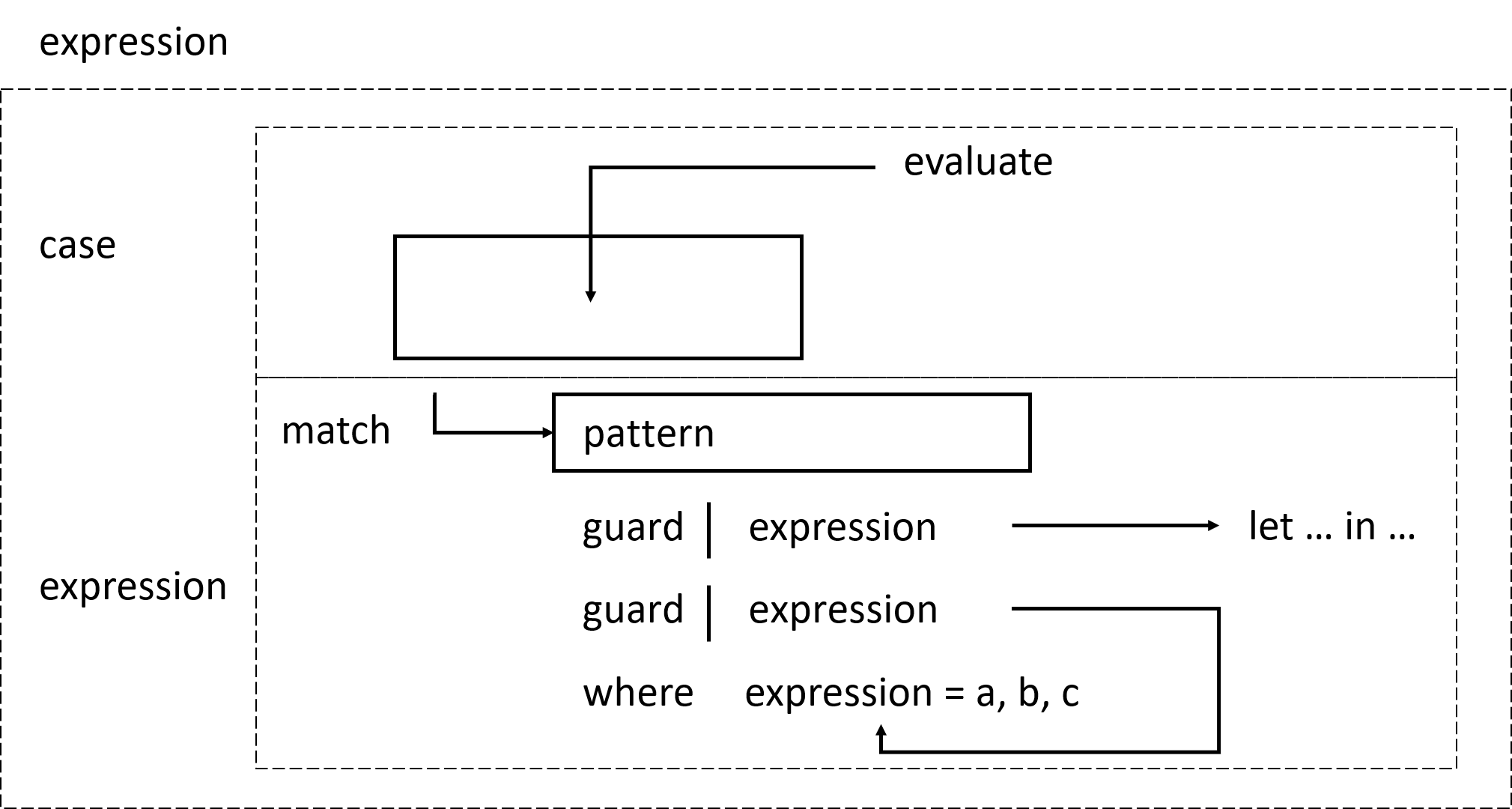
Nhiều ngôn ngữ C, C++, Java, … có cú pháp case, đó là cách lấy đặt một biến vào khay rồi thực hiện các khối lệnh tùy theo giá trị của biến đó, và có thể bao gồm cả khối lệnh default để đề phòng biến chứa giá trị nào đó mà chưa có lệnh thực hiện tương ứng.
Haskell tiếp nhận khái niệm này và nâng nó lên một tầm cao mới. Case expression là biểu thức, rất giống với biểu thức if else và let. Không những ta có thể định lượng biểu thức dựa trên những case có thể xảy ra của giá trị biến, mà ta cũng có thể thực hiện pattern matching. Hmmm, lấy một biến, pattern matching nó, sắp xếp các đoạn code dựa theo giá trị của nó, ta đã nghe thấy điều này ở đâu rồi nhỉ? À đúng rồi, pattern matching dựa theo các tham số mà định nghĩa hàm! Vậy thực ra đó là cách viết tiện lợi cho case expression. Hai đoạn code sau cùng thực hiện một công việc và có thể dùng thay thế nhau được:
-- Pattern matching
head' :: [a] -> a
head' [] = error "No head for empty Lists!"
head' (x:_) = x
-- Case expression
head' :: [a] -> a
head' xs = case xs of [] -> error "No head for empty Lists!"
(x:_) -> x
Bạn có thể thấy, cú pháp của case expression khá đơn giản:
case expression of pattern -> result
pattern -> result
pattern -> result
...
expression được match với các pattern. Pattern đầu tiên match đúng với biểu thức thì sẽ được dùng. Nếu xuyên suốt cả case expression mà không tìm được pattern nào thích hợp, lỗi thực thi sẽ được quăng ra.
Trong khi pattern matching với tham số của hàm chỉ có thể được thực hiện khi định nghĩa hàm, thì case expression có thể được dùng gần như mọi nơi. Chẳng hạn:
describeList :: [a] -> String
describeList xs = "The List is " ++ case xs of [] -> "empty."
[x] -> "a singleton List."
xs -> "a longer List."
Chúng rất có ích cho việc pattern matching một đối tượng nào đó ở giữa một biểu thức. Vì pattern matching trong định nghĩa hàm là cách viết tiện cho case expression, ta cũng có thể định nghĩa hàm trên như sau:
describeList :: [a] -> String
describeList xs = "The List is " ++ what xs
where
what [] = "empty."
what [x] = "a singleton List."
what xs = "a longer List."
Kết thúc bài 3
Tác giả
Vũ Tuấn Hải - Monadotory